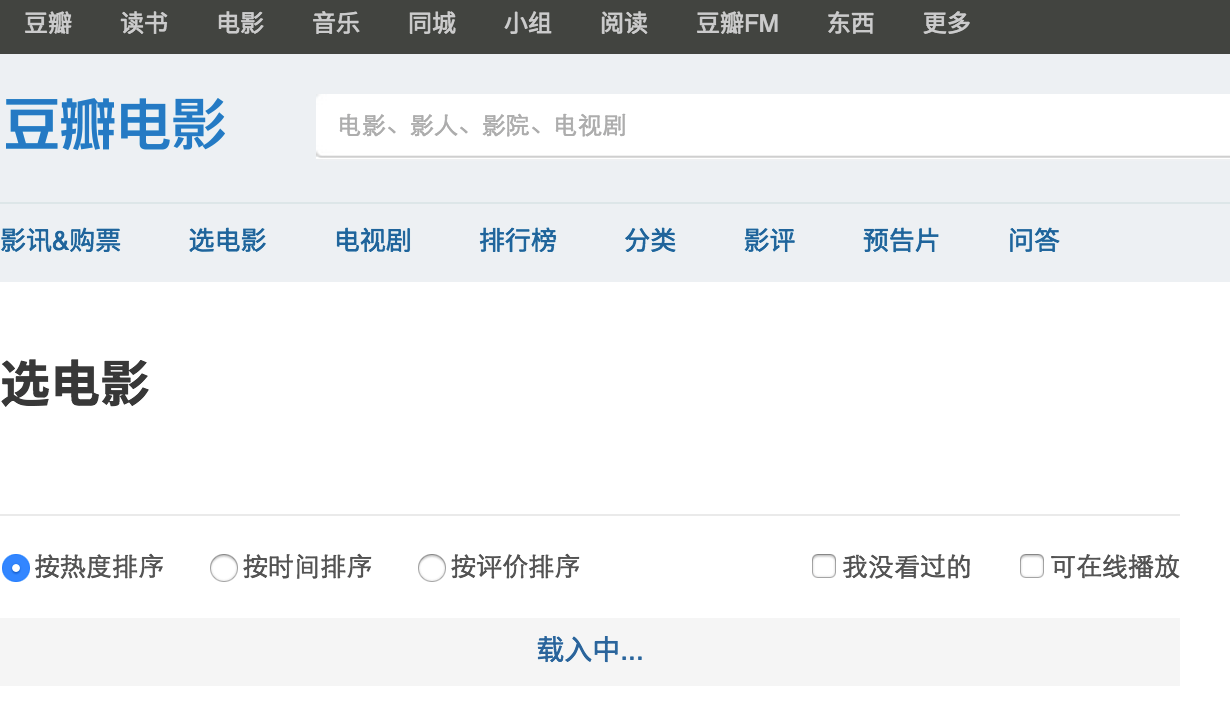
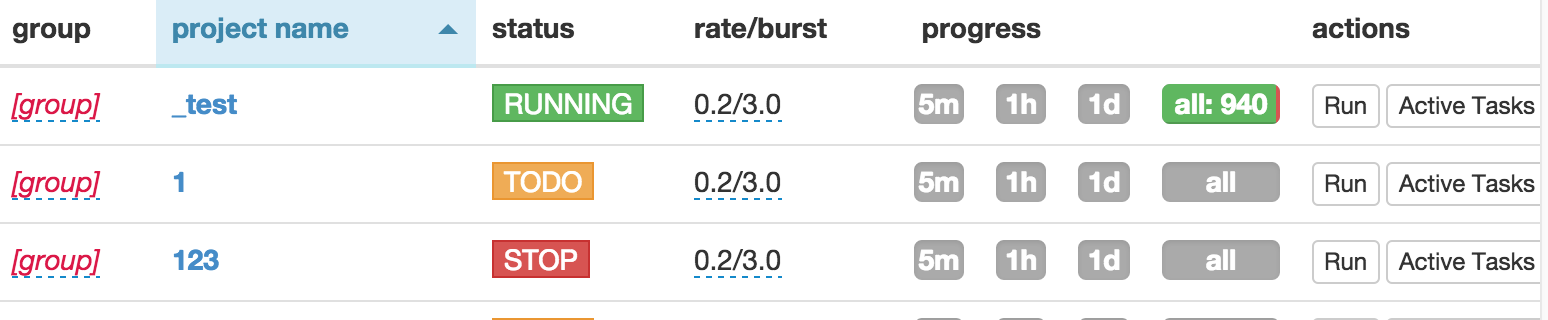
classHandler(BaseHandler): defon_start(self): self.crawl('http://movie.douban.com/explore', fetch_type='js', callback=self.phantomjs_parser) defphantomjs_parser(self, response): return [{ "title": "".join( s for s in x('p').contents() ifisinstance(s, basestring) ).strip(), "rate": x('p strong').text(), "url": x.attr.href, } for x in response.doc('a.item').items()]
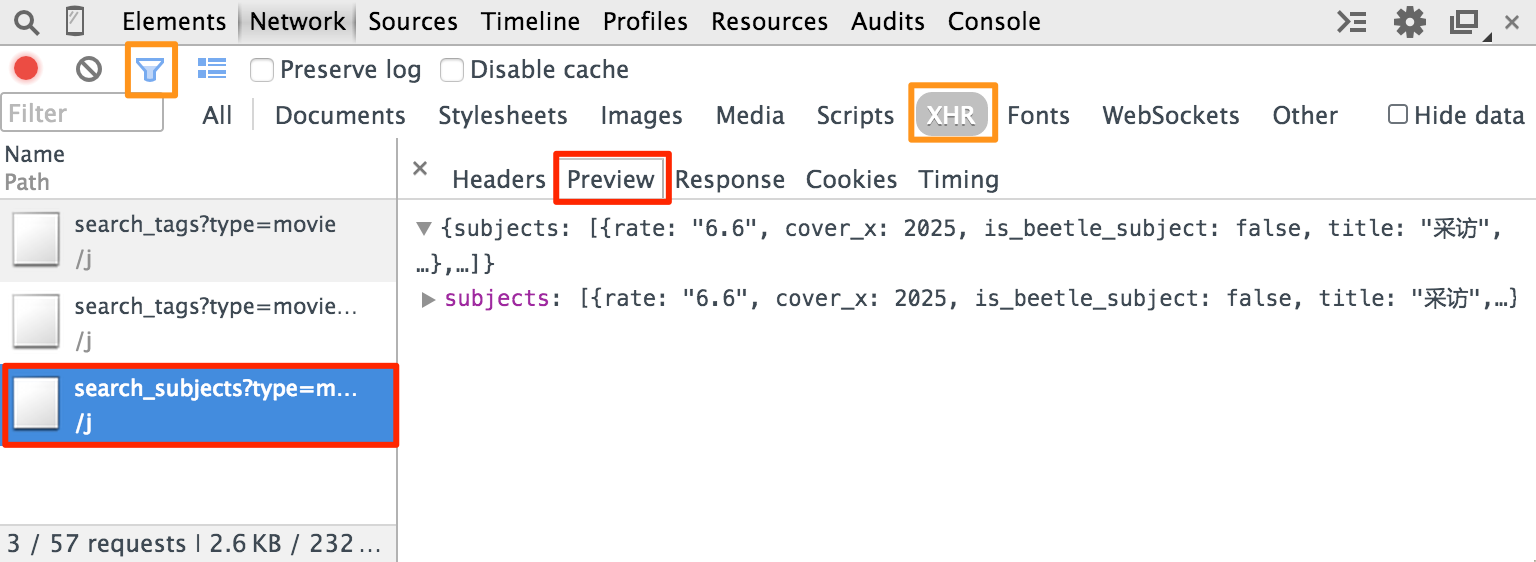
在上一篇教程中,我们使用 self.crawl API 抓取豆瓣电影的 HTML 内容,并使用 CSS 选择器解析了一些内容。不过,现在的网站通过使用 AJAX 等技术,在你与服务器交互的同时,不用重新加载整个页面。但是,这些交互手段,让抓取变得稍微难了一些:你会发现,这些网页在抓回来后,和浏览器中的并不相同。你需要的信息并不在返回 HTML 代码中。
@config(age=10 * 24 * 60 * 60) defindex_page(self, response): for each in response.doc('a[href^="http"]').items(): if re.match("http://movie.douban.com/tag/\w+", each.attr.href, re.U): self.crawl(each.attr.href, callback=self.list_page)
deflist_page(self, response): for each in response.doc('').items():
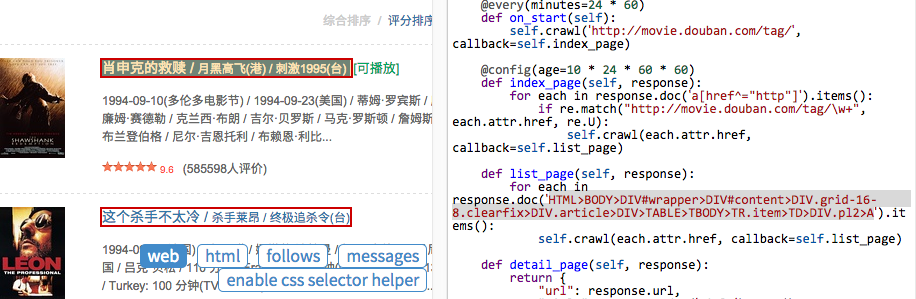
点击一个电影的链接,CSS选择器 表达式将会插入到你的代码中,如此重复,插入翻页的链接:
1 2 3 4 5 6
deflist_page(self, response): for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV>TABLE TR.item>TD>DIV.pl2>A').items(): self.crawl(each.attr.href, callback=self.detail_page) # 翻页 for each in response.doc('HTML>BODY>DIV#wrapper>DIV#content>DIV.grid-16-8.clearfix>DIV.article>DIV.paginator>A').items(): self.crawl(each.attr.href, callback=self.list_page)
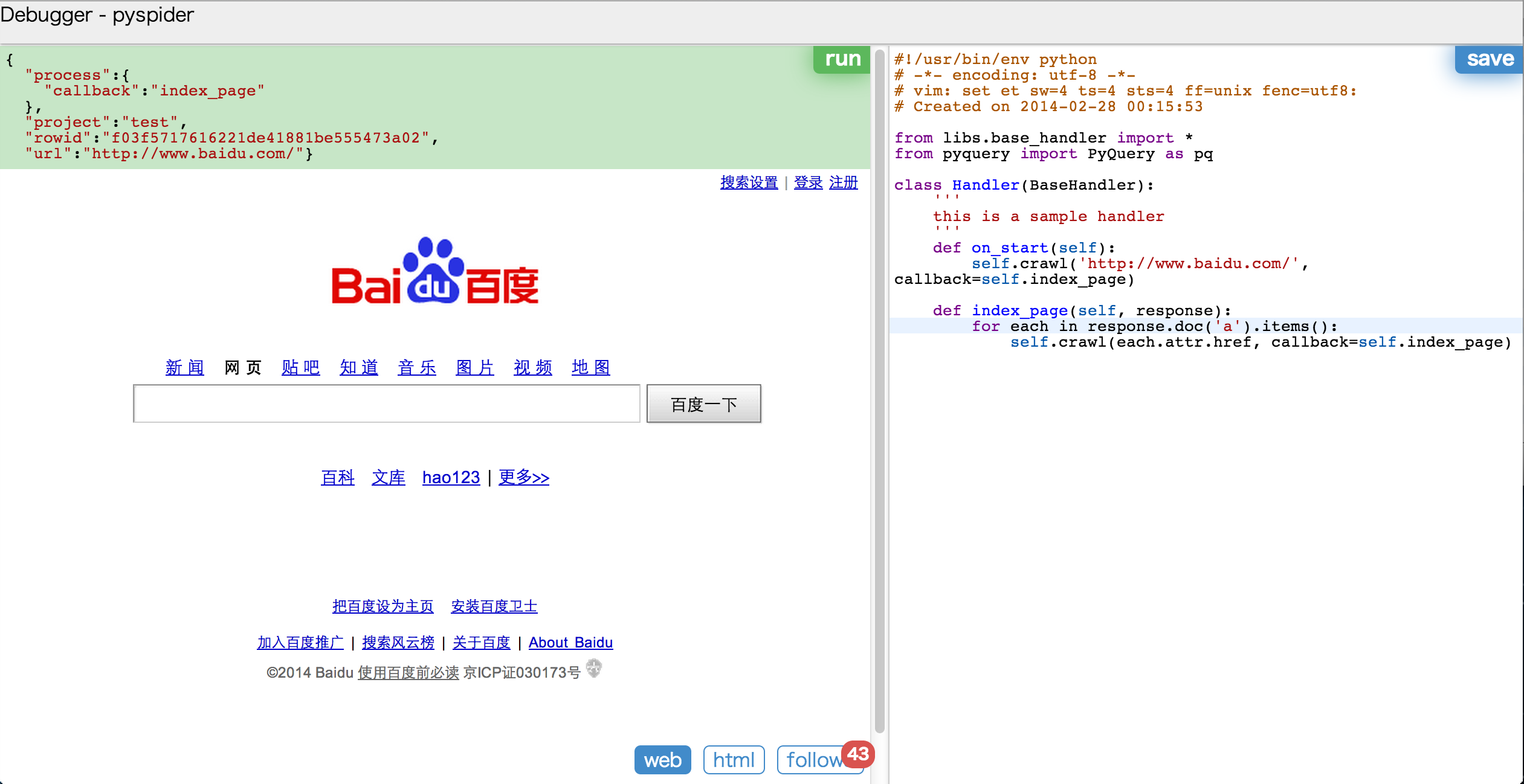
classHandler(BaseHandler): ''' this is a sample handler ''' @every(minutes=24*60, seconds=0) defon_start(self): self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10*24*60*60) defindex_page(self, response): for each in response.doc('a[href^="http://"]').items(): self.crawl(each.attr.href, callback=self.detail_page)